◎ 오라클 설치 환경
◎ 오라클 설치방법
1. Oracle 설치에 필요한 rpm 패키지 설치(없으면 깐다)
아래 명령을 복붙해서 설치
2. Oracle 설치 위한 환경 설정
# vi /etc/sysctl.conf //아래값보다 큰 경우에만 적용
# /sbin/sysctl -p // 상위 설정 변경값 반영(필수) 아래와같이 뜰꺼임 (확인용도)
3. JAVA 설치 (Root 계정 사용 7,8버전 추천)
https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
(자바파일 설치 링크)
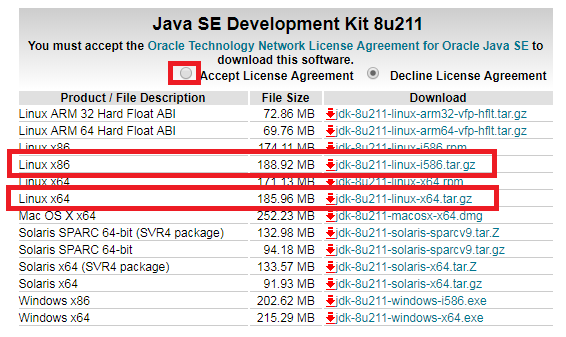
Aceept 체크 후 linux x86 ,64 자기의 OS의 맞춰서 Tar 로 다운 ( 저는 tar가 편해서 이렇게함)
그후 압축을 압축을 풀면 jdk1.8.0_211 폴더가 생겼을 거임 그 폴더를 원하는 경로에 넣어주고 JAVA 폴더로 심볼릭 링크를 생성하면됨. 전 /usr/ 에 옮기고 JAVA 심볼릭 링크를 만듬
위와 같이 명령어를 치면 아래 처럼 구조가 되있을거임
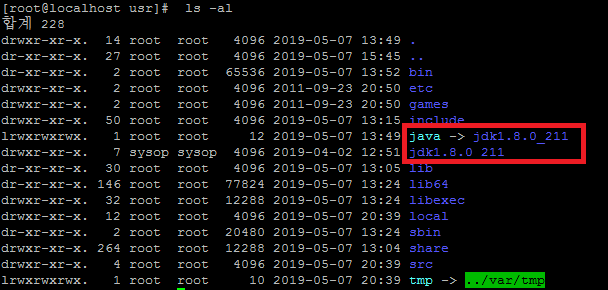
P.S 심볼릭 링크를 만드는 이유는 여러가지가 있겠지만 나중에 JDK 버전이 업데이트 됬을 시 환경 설정을 변경하지 않고 심볼릭 링크의 내용만 수정해 주면 된답니다.
이제 설치된 JAVA 파일을 계정에 등록해줘야 사용할수 있어서 등록해줌.
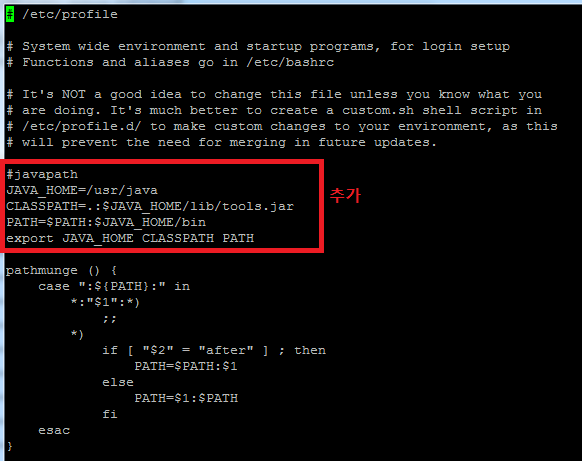
그리고 리눅스에 기본적으로 설정된 java 명령어 위치의 인식을 피하기 위해 /usr/bin 디렉토리의 java 파일 이름을 바꿔줍시다. 그 후 source 명령어를 사용해 /etc/profile의 내용을 현제 쉘에 적용시킵니다. 그리고 java, javac 명령어로 버전을 확인해서 설치된 버전이 출력되면 제대로 설치 된겁니다.

이렇게하면 자바 설치는 완료됬습니다. 오라클설치파일은 자바로 돌아가서 자바를 설치해야 설치가 가능합니다.
4. Oracle 관리자 계정 생성 (필수)
5. Oracle 계정 Profile 수정 ( oracle 계정 사용 , 필수)
6. Oracle 11gr2 Release 2 다운로드 및 압축 풀기(Root 계정 사용, 필수)
▼ 오라클 홈페이지 11gR2 설치링크
https://www.oracle.com/technetwork/database/enterprise-edition/downloads/index.html
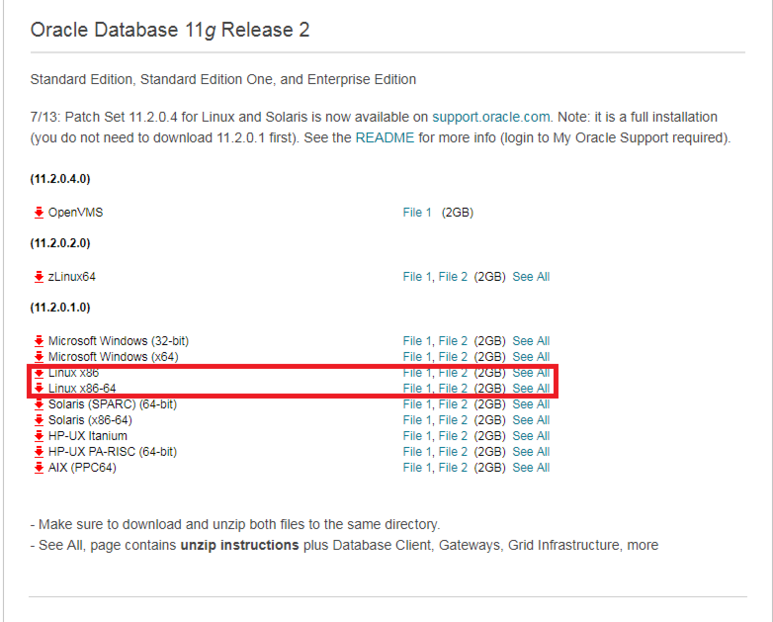
리눅스 버전에 맞는 파일을 설치하면 되겠습니다.

이렇게 아무 폴더나 다운받으시고 2 파일의 압축을 풀어주시면 database 라는 폴더가 생길겁니다.
7. 압축 푼 파일 database 폴더 oracle:oracle 권한 부여 (Root 계정 사용 , 필수)
8. 화면 권한 부여 (Root 계정 사용 , 필수)
9. oracle 계정 선택 (필수)
10. runInstaller 실행(Oracle 계정 사용, 필수)
11. 이메일 설정
- 이메일 설정 체크박스 해제/메시지 박스 나오면 OK.

12. 설치 옵션 선택
- Database 생성 및 구성 선택.

13. Desktop vs. Server Class 선택
- Server Class 선택.

14. DB 운영 선택
- 단독 인스턴스 DB 선택.

15. Typical vs. Advanced install 선택
- Advanced install 선택.

16. 언어 선택
- Korean 추가.

17. 에디션 선택
- Standard Edition 선택.

18. $ORACLE_HOME, $ORACLE_BASE 확인
- .bash_profile과 동일한지 확인.

19. 인벤토리 설정
- /oracle/oraInventory로 경로 설정.
- oinstall로 그룹 설정.
- 메시지 박스에서 Yes 선택.

20. 데이터베이스 타입 선택
- General Purpose / Transaction Processing 선택.

21. DB명 및 SID 설정
- 다른 인스턴스 추가가 아니라면 동일하게 입력.

22. 메모리 설정
- Enable Automatic Memory Management 체크.

23. 문자셋 선택
- KO16WIN949 선택.

24. 보안 설정
- Assert all new security settings 체크.

25. Oracle Enterprise Manager 11g Grid Control 선택
- 그냥 다음으로 PASS.

26. File Storage 선택
- File System 선택.
- /oradata 입력.

27. 자동 백업 선택
- Do not enable automated backups 선택.

28. 계정 암호 설정
- Use the same password for all accounts 선택 후 암호 입력.

29. SYSDBA, SYSOPER 그룹 선택
- 둘다 dba로 선택.

30. 설치 요구사항 체크
- 패키지가 상위버전이 깔린 경우 Failed가 뜨는 건지도...
- pdksh은 직접 받아서 깔아야 한다고도...
(http://rpm.pbone.net/index.php3/stat/4/idpl/2398776/com/pdksh-5.2.14-8.i386.rpm.html)

※ 이후 진행은 시키는 대로...
◎ 오라클 원격(외부) 접속 허용
▼ 내용
보통 linux (CentOS 6.9) 설치하면 방화벽은 따로 안막혀있다. 그런데 오라클 설치하고 원격으로 접속하려 하면 자꾸 접속이 안되있다. 리스너도 start 했고 db도 startup 했는데 원격으로 접속이 안된다면.
Port 번호가 막혀있는거다. 그래서 port번호를 열어줘야한다.
'데이터베이스 > ORACLE' 카테고리의 다른 글
| ORACLE - 특정테이블 다른계정 권한주기 , 계정 만들기 ,패스워드변경 (0) | 2019.03.28 |
|---|---|
| ORACLE - sessions,processes 확인 및 변경 (3) | 2019.03.27 |
| 오라클 실행계획 문법 (0) | 2019.02.28 |
| 오라클 메모리 누수? , full scan시 메모리 누수 문제 (0) | 2019.02.28 |
| 오라클 데이터베이스 에러 (ORA-01578 , ORA-01110 , ORA-26040) (0) | 2019.02.28 |









